TL;DR: Editing long videos coherently via neural video fields.
Abstract
Diffusion models have revolutionized text-driven video editing. However, applying these methods to real-world editing encounters two significant challenges: (1) the rapid increase in graphics memory demand as the number of frames grows, and (2) the inter-frame inconsistency in edited videos. To this end, we propose NVEdit, a novel text-driven video editing framework designed to mitigate memory overhead and improve consistent editing for real-world long videos. Specifically, we construct a neural video field, powered by tri-plane and sparse grid, to enable encoding long videos with hundreds of frames in a memory-efficient manner. Next, we update the video field through off-the-shelf Text-to-Image (T2I) models to impart text-driven editing effects. A progressive optimization strategy is developed to preserve original temporal priors. Importantly, both the neural video field and T2I model are adaptable and replaceable, thus inspiring future research. Experiments demonstrate that our approach successfully edits hundreds of frames with impressive inter-frame consistency.
Pipeline
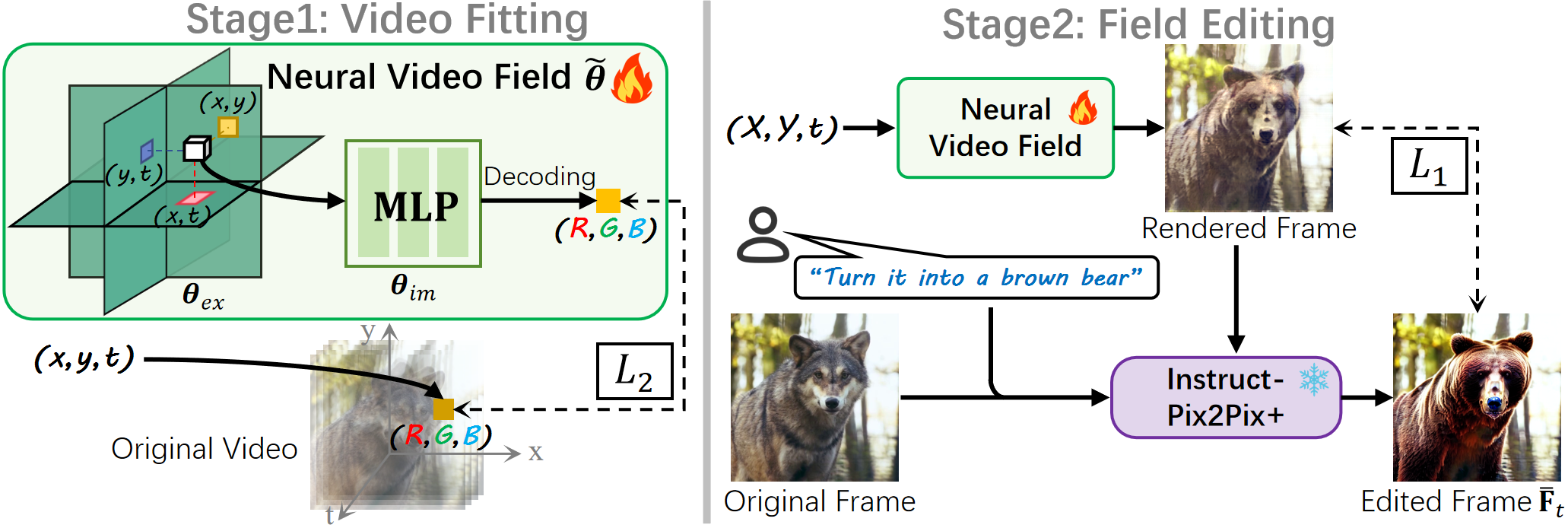
Left, Video Fitting Stage: we train a neural a video field to fit a given video for temporal priors.
Right, Field Editing Stage: The trained neural video field renders a frame, which is then edited by a pre-trained T2I model (e.g., Instruct-Pix2Pix+). We use it to optimize the trained field to impart editing effects.
Long Video Editing Results
More Results (Short Videos)